

By Martino Jerian – CEO and Founder at Amped Software
As the CEO and Founder of a company that develops forensic video enhancement software used by law enforcement agencies and private forensics experts all over the world, one of the most common questions I receive is the following: “How can I justify to the court the fact that I processed an image or video used as evidence?”.
The purpose of this article is to give a definitive and clear answer to this question.
Image quality is the most critical issue with video evidence
Photos and videos are the most powerful kind of digital evidence. If we think about footage coming from video surveillance, images from social media, or extracted from mobile devices during investigations, there are very few legal cases where there’s not some evidence of this type. Furthermore, video is the only form of evidence that can very often reply to all the questions of the 5WH investigation mode: who, what, where, when, why, and how.
Last year, we conducted the survey “The State of Video Forensics 2022” among our users and other video forensics practitioners. The vast majority of respondents mentioned “low image quality” as the main issue working with video evidence, followed by proprietary formats used in video surveillance systems, the number of cases they have to deal with, and the difficulties in properly interpreting video evidence.
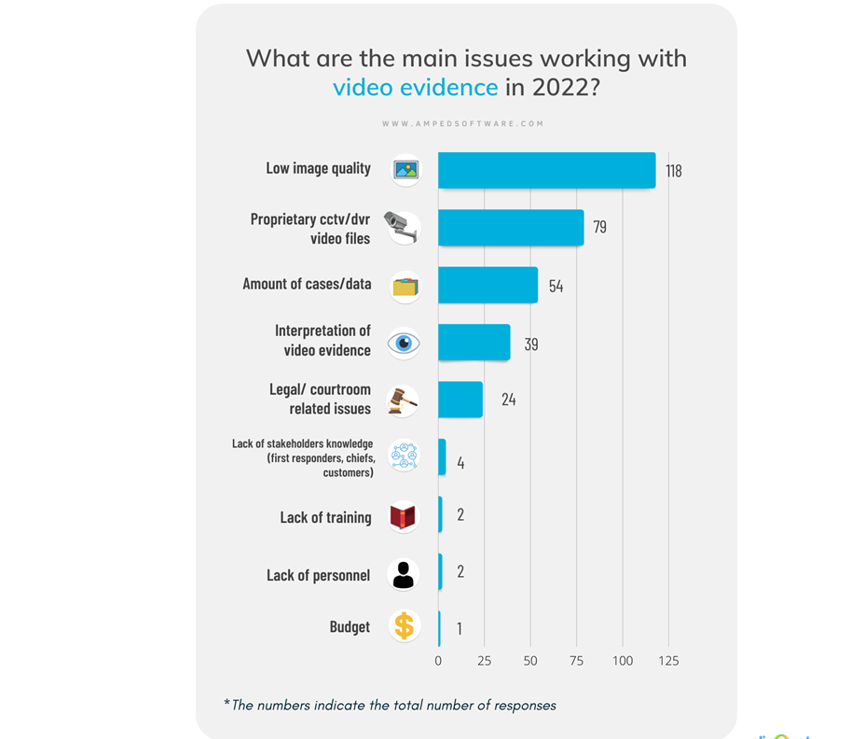

It is clear that we need to tackle this issue in some way to restore and clarify images and videos during investigations: however, it’s clear that we are not editing our family vacation photos to show a nice sunset on the sea. We are working with evidence that can potentially free a criminal or convict an innocent if mishandled. We must ensure the utmost scientific rigor for the sake of justice. An analyst with the right tools, technical preparation, and workflow can enhance the image in a way that can help the trier of fact and be accepted in court.
Forensic image enhancement is important to show things as they really are
A digital image is created by a sequence of physical and digital processes that ultimately produce a representation of light information in a specific moment in a specific place, as a sequence of 0s and 1s. The technical limitations of the imaging system will introduce some defects that will make the image different compared to the original scene, and often less intelligible during investigations. It’s of fundamental importance to understand how these defects are introduced, and in which order to correct them to obtain a more accurate and faithful representation of the scene.
A very straightforward example is the lens distortion introduced by wide-angle lenses: straight walls appear curved in the image because of the features of the camera optics. Since the actual walls are straight, and not curved, the distortion correction allows producing an image that is a more accurate representation of the real scene.


However, normally an image or video presents multiple issues at the same time, and correcting them in the right order is necessary to get a result that provides the best quality, and it’s scientifically valid.
To understand how to do so, we can use the image generation model: it represents a conceptual understanding of how the light coming from a scene in the physical world is converted into an image, and in the case of a digital image (or video) ultimately a sequence of 0s and 1s.
The picture below represents the typical image generation model for a video surveillance system. Different systems can be slightly different or, in the case of a digital camera or a mobile phone, way simpler, but the general concepts hold.
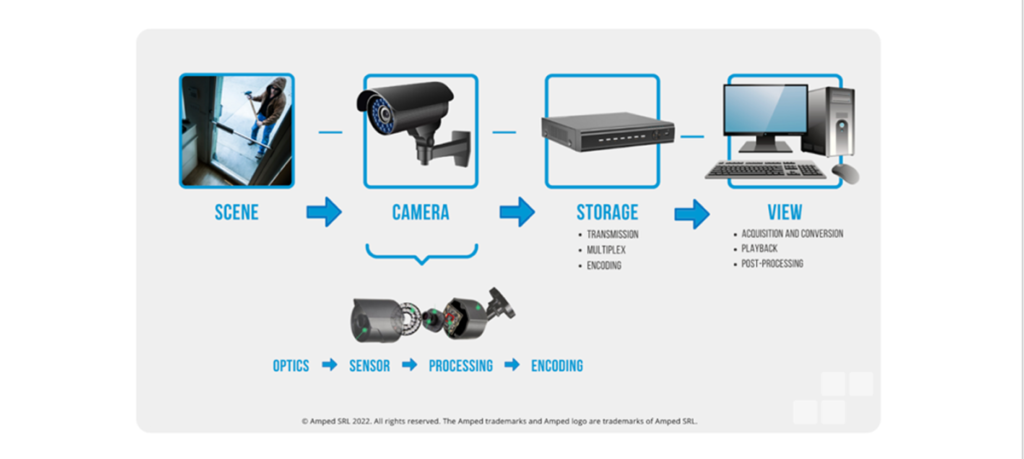

It’s out of the scope of this article to go into detail about every single step, so we’ll give just a quick overview of the main processes.
The light coming from the scene passes through the camera optics, then hits the sensor, which converts the light into a digital signal; this is then processed in various ways inside the camera and encoded into a usable format. In the storage phase, the signal coming from the camera is transmitted, potentially multiplexed with signals from other cameras, and encoded in some way by the DVR. While at this point, the image has been technically generated, further processing is often needed for the video to be played by the operator; depending on the system, acquisition, conversion, and playback are typical steps that need to be taken into account.
At every step, different technical limitations introduce different defects. Many of the issues are actually coming from the camera phase and its sub-phases: optics, sensor, processing, and encoding. Many of the issues are due to the combination of the camera’s features and those of the captured scene. For example, if we try to understand why a moving car appears blurred in an image, it could be because of the features of the real scene (the car was speeding) or the camera (the shutter speed of the camera was too low). It’s easy to understand that it’s actually a combination of the two: the shutter speed was too low for the speed of the car. Similar considerations could be made in many other cases, for example for a scene that is too dark or too bright.
The scientific workflow for forensic video enhancement
In practice, how can we tackle these issues?
First of all, it’s very important to understand the purpose of video analysis. Image enhancement is just a means, not an end. Generic requests such as “please enhance this image”, or “tell me everything interesting you can find in this video” are not enough. The most common requests on footage are either understanding the dynamics of an event (for example “understand which subject started the fight”) or identifying someone (typically through face comparison, or identifying a car by its license plate).
Depending on the questions, the processing and the results will vastly differ. In general, our objective is not to have a more pleasant image, it is to show better the information which is already inside the image, but made difficult to see because of its defects.
Once we know what we are looking for, we need to understand the issues affecting the image that – if removed or attenuated – can help reach our objective. It must be said that it’s not always possible to resolve all issues. If the image has too low resolution, or it’s too aggressively compressed, there is very little to do, since the information is not there in the first place. However, there are certain kinds of defects that can be modeled appropriately in a mathematical way, and inverting this model allows us to recover the underlying information pretty well. Examples of this are, for example, the correction of optical distortion, or deblurring subjects that are moving too fast or are out of focus.


It’s important to remember that all the algorithms that we use, and the overall process, must follow a strict scientific workflow. The methodologies should be as accurate as possible, which means correct, and free as much as possible from errors and bias. The processes should be repeatable – the analyst should be able to repeat the analysis in another moment and get the same results – and reproducible – another expert with the right competency and tools should be able to replicate the outcome. If we are not able to get the same results again and again, that’s not good for science.
There’s a lot of hype currently about the use of Artificial Intelligence (AI) for many different applications. There are impressive results of image enhancement with AI, but with the current technologies, it’s very dangerous to use them on video evidence. They could be used, with the proper safeguards in place, as investigative leads, but using AI-enhanced evidence could introduce bias depending on how we trained the system and the results won’t be explainable in court.
Sam Altman, CEO of OpenAI, recently said “ChatGPT is incredibly limited, but good enough at some things to create a misleading impression of greatness. It’s a mistake to be relying on it for anything important right now. It’s a preview of progress; we have lots of work to do on robustness and truthfulness.” The same can be said about enhancing images with AI. We thoroughly tested AI face enhancement on very low-quality images: while they “seem” to get great results, the “enhanced” subjects didn’t match the actual people.
In the image below you can see some images of celebrities enhanced with AI (first row) and enlarged with a standard bicubic interpolation. They seem pretty good, but if you look at them carefully, they can be pretty misleading.


Finally, the defect should be corrected in the opposite order in which they are introduced in the image generation model. There’s a mathematical explanation to this, but we can understand it at an intuitive level with an analogy: when we dress up, we first wear socks and then shoes. Undressing requires taking off shoes first, and then socks (reverse order).
How successful is forensic video enhancement?
Forensic video enhancement can get very good results, but only if the information is already present in the original data. If so, we can attenuate the defects and amplify the information of interest. If the information is not there, we can not (and we should not, given the forensic context) create new information, which is exactly what techniques based on AI usually do.
The success of enhancement depends on several factors. First of all, what we want to obtain: making a low-resolution face useful for identification is typically more difficult than understanding the type or the color of a vehicle. Then, we need to understand how much “good” data we have: the number of pixels in the area of interest, the kind of compression, how many frames or images, and the overall issues affecting the images.
In 2021 we ran a survey with our users, asking them about how often they can get useful results with enhancement. In 27% of the cases, they were able to get good results, and in 31% of the cases partial results, making enhancement useful – at least in part – in 58% of the cases. In the remaining situations there was no useful information at all in the image (20%), or they thought there was something, but they weren’t able to get it (22%); in this last case probably more training could have helped to improve the results.
Authenticity is not originality
An original image is defined as an image whose data is complete and unaltered since the time of acquisition. An authentic image, on the other side, is an image that is an accurate representation of what purports to be. Both are very important concepts to keep in mind while working with video evidence. While the two may be related, one does not necessarily imply the other.
Coming back to our initial question “How can I justify to the court the fact that I processed an image or video used as evidence?”
The image generation model allows us to give a very simple reply: by understanding how defects are created and correcting them, we can obtain a more accurate representation of the scene (or subjects, or objects) of interest, compared to the original image or video. Because walls are straight, and not curved, and real-world license plates are sharp, not blurred.
Perhaps, then, is the enhanced image more authentic than the original one?
Martino Jerian – CEO and Founder at Amped Software